Research · 12 min read
We Trained a Domain Detector for Drones. One Class Collapsed to Zero.
January 17, 2026
COCO-80 has no class for drone. No class for person_aerial. No class for landing_pad or powerline. That is not a gap we can paper over with prompt engineering — it is a hard limit of the label set the weights were trained on. So we replaced it.
Over three training rounds we built a 9-class domain detector (drone, person_aerial, vehicle, bicycle_motorcycle, landing_pad, powerline_pole, person, animal, boat) tuned for the aerial autonomy use case. We trained on 48,000 images, used YOLOv8n as the base, and learned something important along the way: the biggest failure mode is not the architecture, the learning rate, or the number of epochs. It is class imbalance. One of our classes collapsed to near-zero during training because we did not catch it.
The setup: why aerial perception is different
A drone camera sees the world at angles and scales COCO was not designed for. People become small blobs at 30 m altitude. Vehicles look like rectangles with no distinguishing features. A drone seen by another drone is a 15-pixel smear. Standard ImageNet-pretrained detectors handle the common cases (full-frame people, large cars from the side) but fail on the overhead/oblique aerial regime.
We needed a detector that could fire on exactly those cases: distant people from altitude, vehicles from above, and — critically — other drones in the frame for counter-UAS and deconfliction.
Round 1: 18,000 sim frames from Isaac
We started with pure simulation data. Using NVIDIA Isaac Sim we generated 18,000 labeled frames across three indoor environments (office, warehouse, hospital), scripting drone trajectories and projecting known object poses through the camera model to produce perfect bounding boxes with no human labeling.
The results looked great: mAP50 = 0.471, vehicle AP50 = 0.895, person AP50 = 0.894. We ran at 55 FPS on an RTX 5090 (18 ms per frame) with an ONNX-exported model. We were cautious about the numbers — sim val is easy; there is no sensor noise, no compression artifacts, no lighting variation beyond what we scripted.
But person_aerial AP50 was 0.047 and drone AP50 was 0.047. The sim scenes did not have enough examples of those two classes at aerial angles to learn them well.

Round 2: 343,000 free labels from VisDrone — and the collapse
VisDrone2019-DET is a public aerial-footage dataset with 6,471 train and 548 val images, 382,000 annotated boxes shot from commercial drones over urban scenes. Person_aerial, vehicle, bicycle, motorcycle — all labeled. Free real-world distribution. We merged it in.
Our merged training set grew to 24,500 images and 364,000 boxes. Person_aerial jumped from 0.047 to 0.377 AP50. Vehicle held at 0.755. Bicycle_motorcycle appeared at 0.365. These were genuinely impressive gains.

Drone AP50 dropped from 0.047 to 0.010. The class had not just stagnated — it had nearly vanished.
The diagnosis: 3.5% is not enough
VisDrone has no drone-as-target labels. The dataset is shot by drones looking down at streets; there are no other drones in the frame. When we merged our 12,000 drone boxes from sim into a 343,000-box VisDrone dataset, drones became 3.5% of the total box count. The model learned to ignore the class.
The fix was oversampling. We duplicated every training image containing a drone box 4× so that drone-containing images accounted for roughly 10% of training samples. The training set grew from 21,471 to 48,717 images.
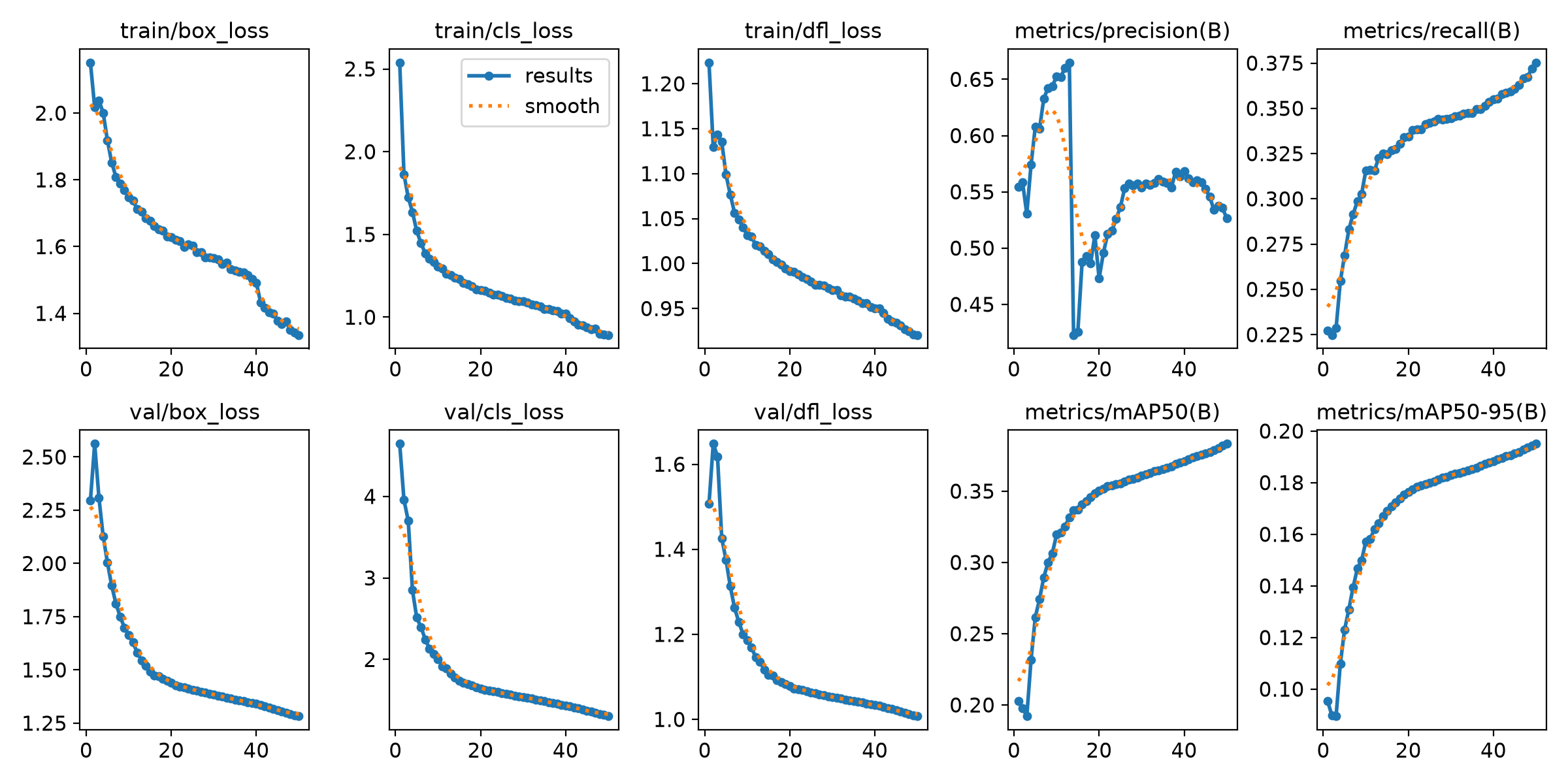
Round 3: the oversampled result
mAP50 on the real-world VisDrone val set: 0.384. Person_aerial: 0.360. Vehicle: 0.752. Bicycle_motorcycle: 0.339. Drone: 0.087.
That 0.087 drone AP50 needs context. The VisDrone val set has zero drone-as-target images; every drone detection at validation time comes from our sim val frames only. So 0.087 is precision when the model fires on drone boxes — not coverage across a large val set. It is meaningful: the v2 model had precision near zero. The v3 model fires correctly when it sees a drone.
What the numbers actually mean
The headline mAP50 trajectory — 0.471 (v1) → 0.376 (v2) → 0.384 (v3) — looks like a small net improvement from pure sim to merged training. It obscures the real story:
- V1's 0.471 was on an easy sim-only val set. The model had never seen a real image. Those numbers do not transfer.
- V2's 0.376 is on a hard real-world val set with 38,000 boxes from actual drone footage. That is a genuine gain, despite looking like a regression in absolute mAP.
- V3's 0.384 adds drone recovery without sacrificing the real-world aerial classes. We got drone back without breaking person_aerial or vehicle.
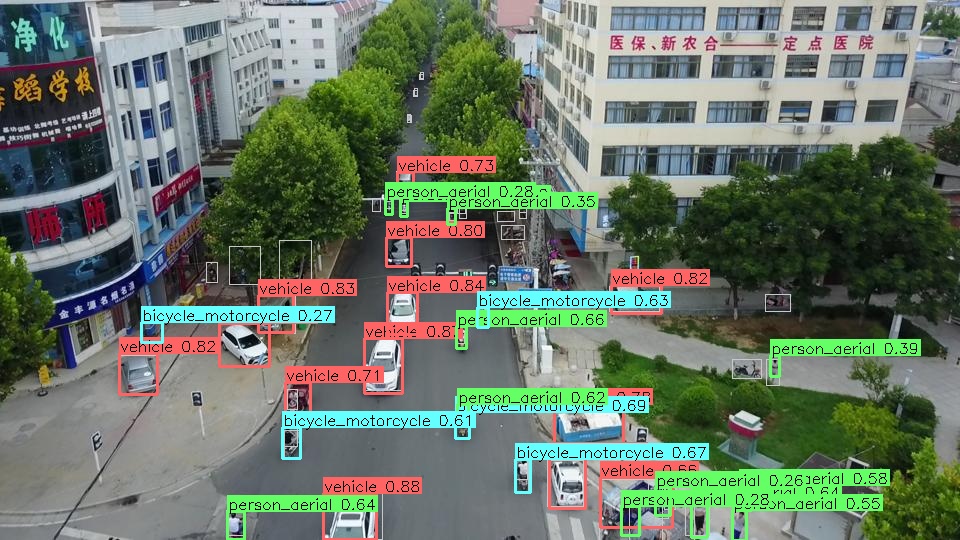
Three things we learned
Sim mAP lies at small sample counts. A 0.471 on 18,000 sim frames with a clean sim val set is not a 0.471 in the wild. Evaluate on out-of-distribution data before claiming any number.
Free labels are worth the class-imbalance fight. VisDrone gave us 343,000 aerial-domain boxes at zero labeling cost. The collapse it caused was real but diagnosable and fixable. The net result — a model that has seen real aerial footage — is dramatically better than sim-only for the classes VisDrone covers.
Class imbalance at 3.5% is a hard floor. We do not know exactly where the threshold is, but below about 5% of boxes the model treats a class as noise. The fix — oversampling the underrepresented images — is simple and effective. Future work: add synthetic augmentation (mosaic, copy-paste) specifically for the rare aerial classes (landing_pad, powerline_pole, animal, boat) which currently have zero training data.
Where the model runs
The ONNX is 12 MB. It runs at 55 FPS on an RTX 5090 and is deployed to Jetson Orin Nano hardware (rover and quadcopter) where it replaces the stock COCO-80 model in the perception pipeline. The model is loaded automatically by the perception layer — no inference code changes required.
Download
The ONNX model is on Hugging Face at astralhf/astral-drone-models:
- yolov8n_domain_v3.onnx — 11.7 MB, YOLOv8n, 9-class aerial detector, ONNX opset 17
Input: 640×640 RGB, normalized to ImageNet mean/std. Output: standard YOLOv8 detection head (xywh + conf + 9-class logits). Classes in order: drone, person_aerial, vehicle, bicycle_motorcycle, landing_pad, powerline_pole, person, animal, boat.
Technical report with all metrics, training curves, and confusion matrices: Domain-Specific Object Detection for Aerial Autonomy.